Нескольким читателям моего блога было интересно узнать «как объединить крон, базу данных и php парсер».
Я постарался написать максимально простой и лаконичный скрипт, чтобы любой новичок смог в нём разобраться. Он состоит всего из одного файла index.php и 50 строк кода.
Я использовал 2 библиотеки:
- RedBean PHP, которая упрощает работу с БД и защищает от SQL инъекций -> читать подробнее
- phpQuery — порт jQuery на PHP, который позволяет добираться до нужных блоков в дебрях документа
Парсить в учебных целях мы будем один сайт о моде и красоте. Остановимся мы только на парсинге 10 статей, чтобы понять суть.
А вот и сам скрипт — файл index.php
require 'db.php'; // подключаем библиотеку ReadbeenPHP и соединяемся с базой данных
require('/phpQuery/phpQuery.php'); // подключаем phpQuery
define('HOST','http://tbeauty.ru'); // сюда мы вписываем адрес сайта-донора, который необходимо спарсить
R::wipe('post'); // удаляем все записи из таблицы post
R::wipe('postprev'); // удаляем все записи из таблицы postprev
$data_site = file_get_contents(HOST); // получаем страницу сайта-донора
$document = phpQuery::newDocument($data_site);
$content_prev = $document->find('.news .post');
// перебираем в цикле все посты
foreach ($content_prev as $el) {
// Парсим превьюшки статей
$pq = pq($el); // pq это аналог $ в jQuery
$h2 = $pq->find('.post-title h2 a')->attr('title'); // парсим заголовок статьи
$link = $pq->find('.post-title h2 a')->attr('href'); // парсим ссылку на статью
$text = $pq->find('.post-content p'); // парсим текст в превью статьи
$img = $pq->find('.wp-post-image')->attr('src'); // парсим ссылку на изображение в превью статьи
// Записываем информацию о превьюшках в базу данных
$post_prev = R::dispense('postprev');
if(!empty($h2)) $post_prev->h2 = strip_tags($h2); // strip_tags удаляет HTML тэги из строки
if(!empty($link)) $post_prev->link = HOST.$link;
if(!empty($text)) $post_prev->text = strip_tags($text);
if(!empty($img)) $post_prev->img = HOST.$img;
R::store($post_prev);
// пробегаемся по всем ссылкам на посты и парсим контент из открытых статей
if(!empty($link)) $data_link = file_get_contents(HOST.$link);
$document_с = phpQuery::newDocument($data_link);
$content = $document_с->find('.broden-ajax-content');
foreach ($content as $element) {
$pq2 = pq($element);
$h1 = $pq2->find('.post-title h1'); // парсим главный заголовок статьи
$text_all = $pq2->find('.article__content .txt'); // парсим контент часть статьи
}
// Записываем информацию о статьях в базу данных
$post = R::dispense('post');
if(!empty($h1)) $post->h1 = strip_tags($h1);
if(!empty($text_all)) $post->text = strip_tags($text_all);
R::store($post);
}
Соединение с БД — файл db.php
require 'libs/rb.php';
R::setup( 'mysql:host=127.0.0.1;dbname=parserlinio','root', '' );
if ( !R::testconnection() )
{
exit ('Нет соединения с базой данных');
}
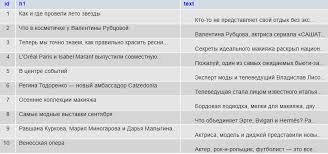
Если мы запустим парсер, то в базе данных автоматически появятся 2 таблички. В таблице postprev запишется информация о превью статей (картинка, заголовок, небольшой текст и ссылка на сам пост).
В таблицу post запишется уже полная информация о статьях.
Вот такая красота в итоге получается.
Таблица postprev

Таблица post
Как работает парсер?
- Подключаемся к нашей базе данных (файл db.php)
- Подключаем библиотеки
- Создаем константу, в которой хранится адрес сайта-донора
- Очищаем таблицы post и postprev в БД. Это нужно для того, чтобы при повторном запуске парсера, данные в таблицах не дублировались. Момент очень спорный. Возможно, можно было сделать проверку на совпадение с данными в БД и уже потом производить запись или назначать статусы (0 – не парсили, 1 — парсили). Если есть мысли, то пишите в комментариях
- Функцией file_get_contents получаем содержимое страницы
- Смотрим, как у сайта-донора устроена разметка постов
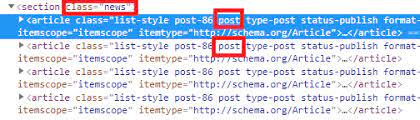
- Перебираем в цикле foreach все посты
- Проверяем разметку превью постов и смотрим, в каких тэгах находятся необходимые данные (заголовок, картинка и т.д.)
- Информацию о превью, которую мы спарсили записываем в БД. Делается это методом dispense библиотеки RedbeenPHP, который принимает всего 1 аргумент – название таблицы.
Причем, если такой таблицы в БД нет, то он сам её корректно создаст - В пункте 8 мы спарсили ссылки на посты. Теперь можно перебрать их в цикле, чтобы спарсить текст внутри статей и заголовоки
- По аналогии с пунктом 9 записываем информацию о статьях в БД
- Теперь вам остается лишь самостоятельно вывести информацию из БД на свой сайт
- Также можно настроить CRON на своем сервере, чтобы файл index.php автоматически запускался, например, раз в неделю.
Делается это в разделе планировщик задач. Также можно попросить помощи у техподдержки хостинга.
P.S. Данный парсер очень простой и его функционал можно расширять до бесконечности.
Тестировался парсер на OpenServer. Версия PHP 5.6. На момент написания статьи всё работало. Если у вас не работает, то возможно у сайта-донора поменялся дизайн и соответственно вёрстка.